[ad_1]
Avec l’appétit toujours croissant des professionnels du référencement pour apprendre Python, il n’y a jamais eu de moment meilleur ou plus excitant pour tirer parti des capacités de l’apprentissage automatique (ML) et les appliquer au référencement.
Cela est particulièrement vrai dans votre recherche de concurrents.
Dans cette colonne, vous apprendrez comment l’apprentissage automatique aide à relever les défis courants dans la recherche de concurrents SEO, comment configurer et former votre modèle ML, comment automatiser votre analyse, et plus encore.
Faisons cela!
Pourquoi nous avons besoin d’apprentissage automatique dans la recherche de concurrents SEO
La plupart, sinon tous les professionnels du référencement travaillant sur des marchés concurrentiels, analyseront les SERP et leurs concurrents commerciaux pour savoir ce que fait leur site pour atteindre un rang plus élevé.
En 2003, nous utilisions des feuilles de calcul pour collecter des données à partir des SERP, avec des colonnes représentant différents aspects de la compétition tels que le nombre de liens vers la page d’accueil, le nombre de pages, etc.
Avec le recul, l’idée était juste, mais l’exécution était sans espoir en raison des limites d’Excel pour effectuer une analyse statistiquement robuste dans le court laps de temps requis.
Publicité
Continuer la lecture ci-dessous
Et si les limites des feuilles de calcul ne suffisaient pas, le paysage a beaucoup évolué depuis, comme nous l’avons maintenant :
- SERP mobiles.
- Des médias sociaux.
- Une expérience de recherche Google beaucoup plus sophistiquée.
- Vitesse de la page.
- Recherche personnalisée.
- Schéma.
- Frameworks Javascript et autres nouvelles technologies Web.
Ce qui précède n’est en aucun cas une liste exhaustive des tendances, mais sert à illustrer la gamme toujours croissante de facteurs qui peuvent expliquer l’avantage de vos concurrents les mieux classés sur Google.
L’apprentissage automatique dans le contexte du référencement
Heureusement, avec des outils comme Python/R, nous ne sommes plus soumis aux limites des feuilles de calcul. Python/R peut gérer des millions à des milliards de lignes de données.
Au contraire, la limite est la qualité des données que vous pouvez intégrer à votre modèle de ML et les questions intelligentes que vous posez à vos données.
En tant que professionnel du référencement, vous pouvez faire la différence décisive dans votre campagne de référencement en coupant le bruit et en utilisant l’apprentissage automatique sur les données des concurrents pour découvrir :
Publicité
Continuer la lecture ci-dessous
- Quels facteurs de classement peuvent le mieux expliquer les différences de classement entre les sites.
- Quelle est la référence gagnante.
- Combien vaut un changement d’unité dans le facteur en termes de rang.
Comme toute entreprise scientifique (des données), il y a un certain nombre de questions auxquelles il faut répondre avant de pouvoir commencer à coder.
Quel type de problème de ML est l’analyse des concurrents ?
Le ML résout un certain nombre de problèmes, qu’il s’agisse de catégoriser des choses (classification) ou de prédire un nombre continu (régression).
Dans notre cas particulier, puisque la qualité du référencement d’un concurrent est dénotée par son rang dans Google, et que ce rang est un nombre continu, alors le problème du ML est un problème de régression.
Indicateur de résultat
Étant donné que nous savons que le problème de ML est un problème de régression, la métrique de résultat est le rang. Cela a du sens pour plusieurs raisons :
- Le rang ne souffrira pas de la saisonnalité ; le classement d’une marque de crème glacée pour les recherches sur [ice cream] ne se dépréciera pas parce que c’est l’hiver, contrairement à la métrique « utilisateurs ».
- Le classement des concurrents est une donnée de tiers et est disponible à l’aide d’outils de référencement commerciaux, contrairement à leur trafic d’utilisateurs et à leurs conversions.
Quelles sont les fonctionnalités ?
Connaissant la métrique de résultat, nous devons maintenant déterminer les variables indépendantes ou les entrées du modèle, également appelées caractéristiques. Les types de données pour la fonctionnalité varieront, par exemple :
- La première peinture mesurée en secondes serait un nombre.
- Le sentiment avec les catégories positive, neutre et négative serait un facteur.
Naturellement, vous souhaitez couvrir autant de fonctionnalités significatives que possible, notamment techniques, de contenu/UX et hors site pour la recherche de concurrents la plus complète.
Qu’est-ce que les mathématiques ?
Étant donné que les classements sont numériques, et que nous voulons expliquer la différence de classement, alors en termes mathématiques :
rank ~ w_1*feature_1 + w_2*feature_2 + … + w_n*feature_n
~ (connu sous le nom de « tilde ») signifie « expliqué par »
n étant la nième caractéristique
w est la pondération de la caractéristique
Utiliser l’apprentissage automatique pour découvrir les secrets des concurrents
Avec les réponses à ces questions en main, nous sommes prêts à découvrir les secrets que le machine learning peut révéler sur vos concurrents.
À ce stade, nous supposerons que vos données (connues dans cet exemple sous le nom de « serps_data ») ont été jointes, transformées, nettoyées et sont maintenant prêtes pour la modélisation.
Publicité
Continuer la lecture ci-dessous
Au minimum, ces données contiendront le classement Google et les données de fonctionnalités que vous souhaitez tester.
Par exemple, vos colonnes peuvent inclure :
- Google_rank.
- Page_vitesse.
- Sentiment.
- Flesch_kincaid_reading_ease.
- Amp_version_available.
- Site_profondeur.
- Internal_page_rank.
- Referring_comains count.
- avg_domain_authority_backlinks.
- title_keyword_string_distance.
Former votre modèle ML
Pour entraîner votre modèle, nous utilisons XGBoost car il a tendance à fournir de meilleurs résultats que les autres modèles de ML.
Les alternatives que vous pouvez essayer en parallèle sont LightGBM (en particulier pour les ensembles de données beaucoup plus volumineux), RandomForest et Adaboost.
Essayez d’utiliser le code Python suivant pour XGBoost pour votre ensemble de données SERP :
# importer les bibliothèques
import xgboost as xgb
import pandas as pd
serps_data = pd.read_csv('serps_data.csv')
# définir les variables du modèle
# vos données SERP avec tout sauf la colonne google_rank
serp_features = serps_data.drop(columns = ['Google_rank'])
# vos données SERPs avec juste la colonne google_rank
rank_actual = serps_data.Google_rank
# Instancier le modèle
serps_model = xgb.XGBRegressor(objective="reg:linear", random_state=1231)
# correspond au modèle
serps_model.fit(serp_features, rank_actual)
# générer les prédictions du modèle
rank_pred = serps_model.predict(serp_features)
# évaluer la précision du modèle
mse = mean_squared_error(rank_actual, rank_pred)
Notez que ce qui précède est très basique. Dans un scénario client réel, vous voudriez tester un certain nombre d’algorithmes de modèle sur un échantillon de données d’apprentissage (environ 80 % des données), évaluer (en utilisant les 20 % de données restantes) et sélectionner le meilleur modèle.
Publicité
Continuer la lecture ci-dessous
Alors, quels secrets ce modèle d’apprentissage automatique peut-il nous révéler ?
Les moteurs de classement les plus prédictifs
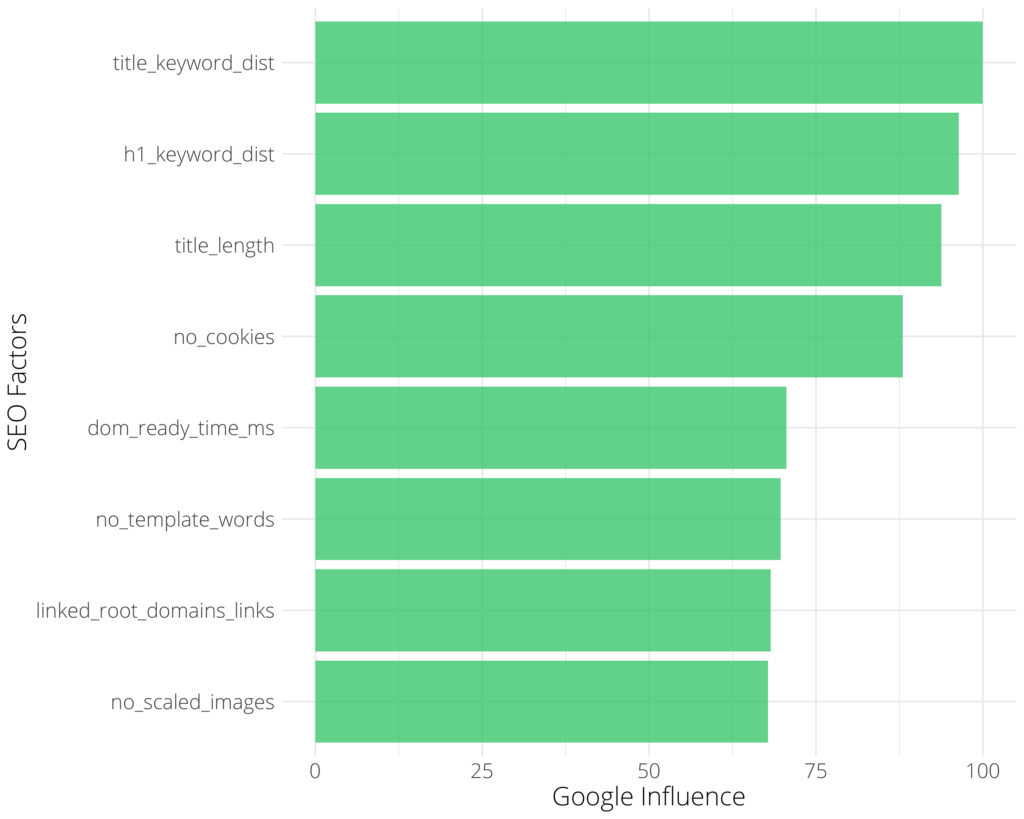
Le graphique montre les caractéristiques SERP ou les facteurs de classement les plus influents par ordre décroissant d’importance.
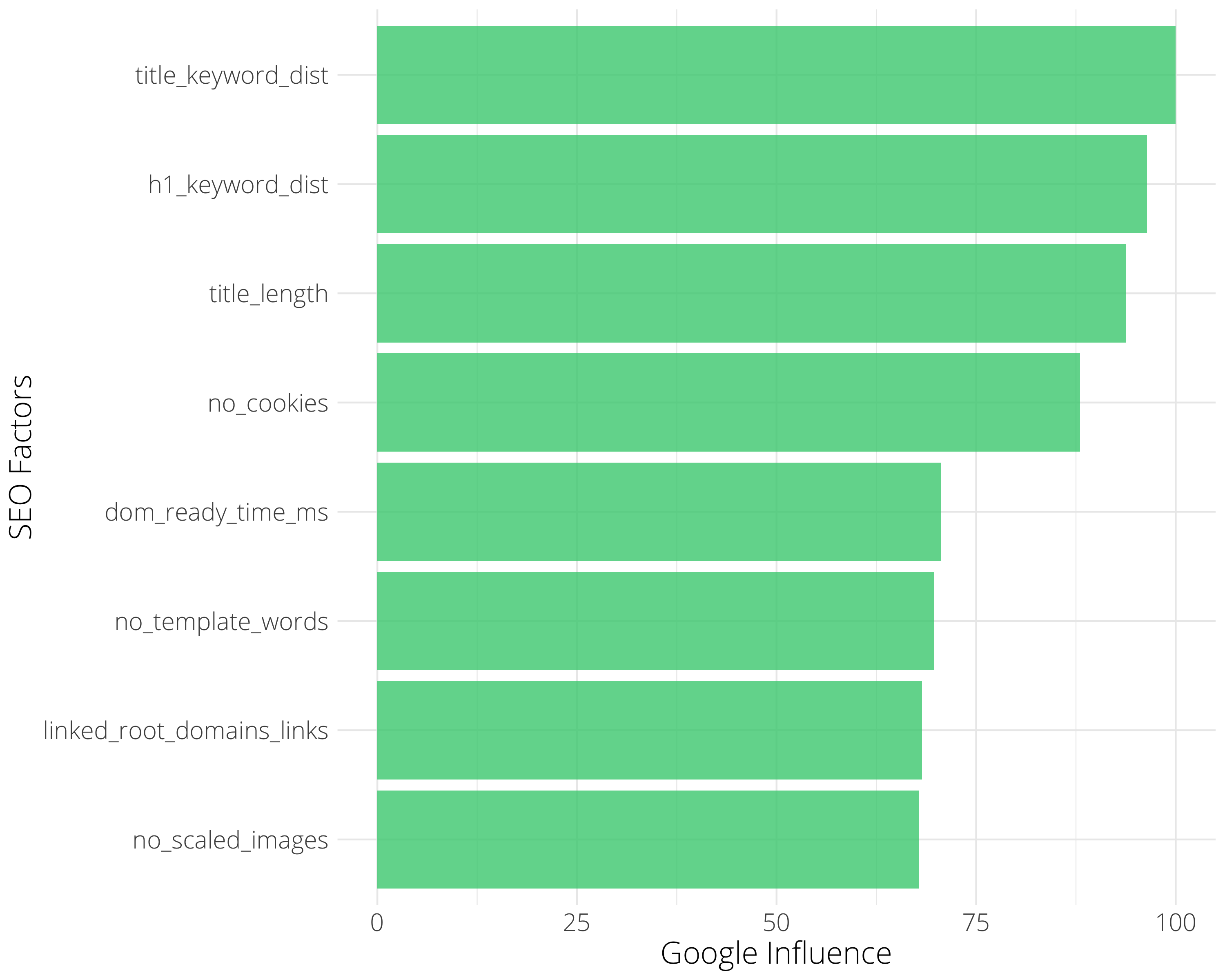
Dans ce cas particulier, le facteur le plus important était « title_keyword_dist » qui mesure la distance de chaîne entre la balise de titre et le mot-clé cible. Considérez cela comme la pertinence de la balise de titre par rapport au mot-clé.
Publicité
Continuer la lecture ci-dessous
Pas de surprise pour le praticien du référencement, cependant, la valeur ici est de fournir des preuves empiriques au public professionnel non expert qui ne comprend pas la nécessité d’optimiser les balises de titre.
D’autres facteurs importants dans cette industrie sont :
- pas de cookies: Le nombre de cookies.
- dom_ready_time_ms: Une mesure de la vitesse de la page.
- no_template_words: compte le nombre de mots en dehors de la section de contenu du corps principal.
- link_root_domains_links: nombre de liens vers les domaines racine.
- no_scaled_images: nombre d’images mises à l’échelle qui doivent être mises à l’échelle par le navigateur pour être rendues.
Chaque marché ou industrie est différent, donc ce qui précède n’est pas un résultat général pour l’ensemble du référencement !
Quelle est la valeur d’un facteur de classement
Dans un autre cas de marché, nous pouvons également voir combien de rangs seront délivrés.
![]()
![]()
Dans le tableau ci-dessus, nous avons une liste de facteurs et le changement de rang pour chaque changement d’unité positif dans ce facteur.
Publicité
Continuer la lecture ci-dessous
Par exemple, pour chaque augmentation d’unité de la longueur de la méta description de 1 caractère, il y a une diminution correspondante du classement Google de 0,1.
Sorti de son contexte, cela semble ridicule. Cependant, étant donné que la plupart des méta-descriptions sont remplies, cela signifierait qu’un changement d’unité par rapport à la longueur moyenne des méta-descriptions entraînerait alors une diminution du classement dans la recherche Google.
La référence gagnante pour un facteur de classement
Vous trouverez ci-dessous un graphique traçant la longueur moyenne des balises de titre pour un secteur différent de celui ci-dessus, qui comprend également une ligne de meilleur ajustement :
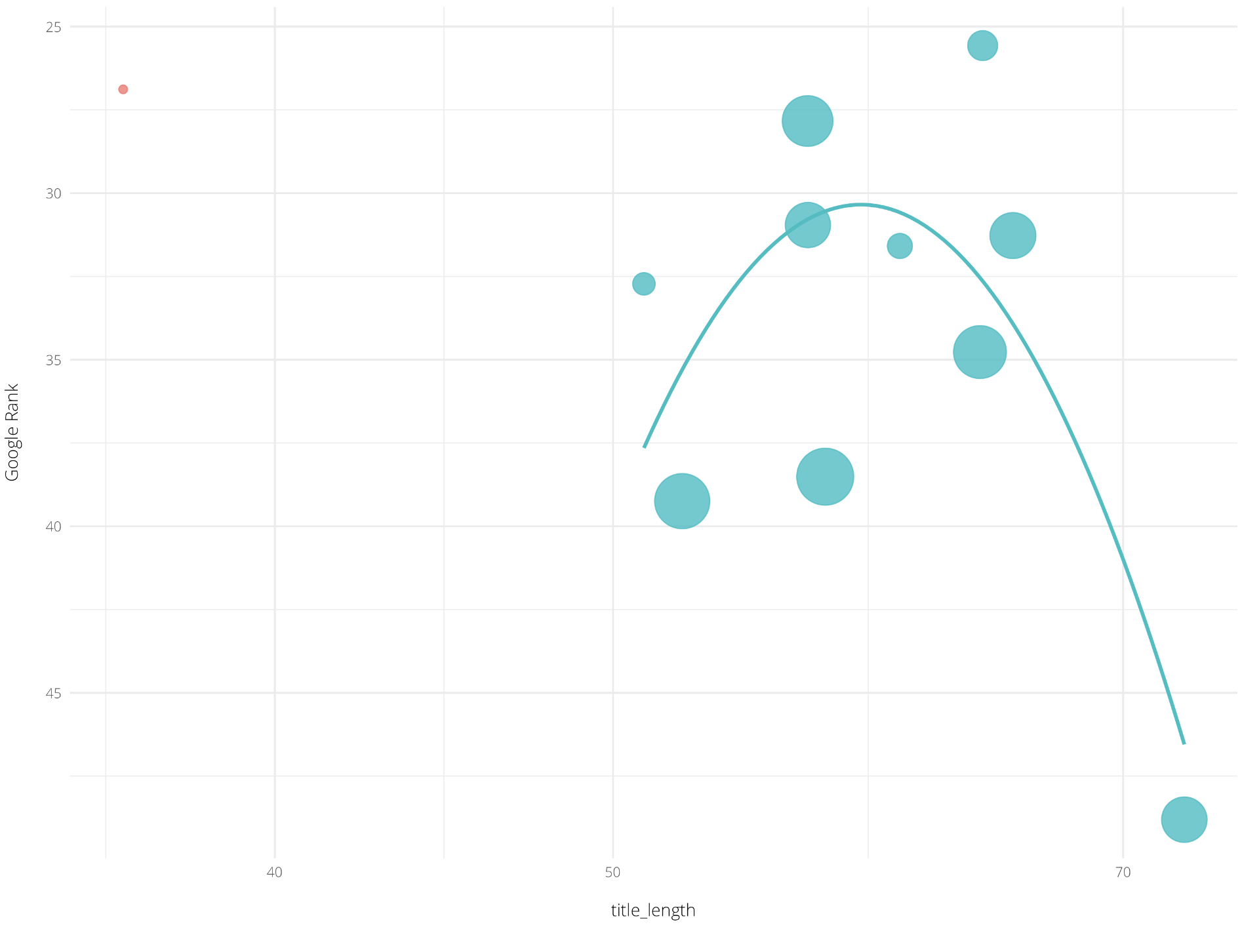
Malgré la recommandation des meilleures pratiques de référencement consistant à utiliser jusqu’à 70 caractères pour la longueur de la balise de titre, les données tracées ci-dessus montrent que la longueur optimale réelle dans cette industrie est de 60 caractères.
Publicité
Continuer la lecture ci-dessous
Grâce à l’apprentissage automatique, nous sommes non seulement en mesure de mettre en évidence les facteurs les plus importants, mais lorsque nous plongeons en profondeur, nous pouvons également voir la référence gagnante.
Automatiser votre analyse de la concurrence SEO avec l’apprentissage automatique
L’application ci-dessus de l’apprentissage automatique est idéale pour obtenir des idées pour diviser le test AB et améliorer le programme de référencement avec des demandes de changement fondées sur des preuves.
Il est également important de reconnaître que cette analyse est rendue d’autant plus puissante lorsqu’elle est en cours.
Pourquoi?
Parce que l’analyse ML n’est qu’un instantané des SERP à un moment donné.
Avoir un flux continu de collecte et d’analyse de données signifie que vous obtenez une image plus fidèle de ce qui se passe réellement avec les SERP pour votre secteur.
C’est là que les systèmes d’entrepôt de données et de tableau de bord spécialement conçus pour le référencement sont utiles, et ces produits sont disponibles aujourd’hui.
Ce que font ces systèmes, c’est :
- Ingérez quotidiennement vos données à partir de vos outils de référencement préférés.
- Combinez les données.
- Utilisez ML pour faire apparaître des informations comme ci-dessus dans un frontal de votre choix comme Google Data Studio.
Publicité
Continuer la lecture ci-dessous
Pour créer votre propre système automatisé, vous déploieriez dans une infrastructure cloud comme Amazon Web Services (AWS) ou Google Cloud Platform (GCP) ce qu’on appelle ETL, c’est-à-dire extraire, transformer et charger.
Expliquer:
- Extrait – Appel quotidien de vos API d’outils de référencement.
- Transformer – Le nettoyage et l’analyse de vos données à l’aide du ML comme décrit ci-dessus.
- Charger – Déposer le résultat fini dans votre entrepôt de données.
Ainsi, la collecte, l’analyse et la visualisation de vos données sont automatisées en un seul endroit.
TL ; DR ?
La recherche et l’analyse de la concurrence dans le référencement sont difficiles car il y a tellement de facteurs de classement à contrôler.
Les tableurs ne sont pas à la hauteur, en raison des quantités de données impliquées (sans parler des capacités statistiques offertes par les langages de science des données comme Python).
Lorsque vous effectuez une analyse des concurrents SEO à l’aide de l’apprentissage automatique, il est important de comprendre qu’il s’agit d’un problème de régression, que la variable cible est le classement Google et que les hypothèses sont les facteurs de classement.
L’utilisation du ML sur vos concurrents peut vous dire quels sont les principaux moteurs, identifier les points de référence gagnants parmi eux et indiquer à quel point vos optimisations peuvent potentiellement améliorer le classement.
Publicité
Continuer la lecture ci-dessous
L’analyse n’est qu’un instantané, donc pour rester au top de vos concurrents, automatisez ce processus à l’aide d’Extract, Transform, Load (ETL).
Plus de ressources:
Crédits image
Toutes les captures d’écran prises par l’auteur, juin 2021
[ad_2]





