Google AI Blog a annoncé KELM, un moyen qui pourrait être utilisé pour réduire les biais et le contenu toxique dans la recherche (réponse à une question sur le domaine ouvert). Il utilise une méthode appelée TEKGEN pour convertir les faits Knowledge Graph en texte en langage naturel qui peut ensuite être utilisé pour améliorer les modèles de traitement du langage naturel.
Qu’est-ce que KELM?
KELM est un acronyme pour Knowledge-Enhanced Language Model Pre-training. Les modèles de traitement du langage naturel comme BERT sont généralement formés sur le Web et d’autres documents. KELM propose d’ajouter un contenu factuel fiable (amélioré par les connaissances) au pré-apprentissage du modèle de langage afin d’améliorer l’exactitude factuelle et de réduire les biais.
 TEKGEN convertit les données structurées du graphe de connaissances en texte en langage naturel connu sous le nom de KELM Corpus
TEKGEN convertit les données structurées du graphe de connaissances en texte en langage naturel connu sous le nom de KELM CorpusKELM utilise des données fiables
Les chercheurs de Google ont proposé d’utiliser des graphiques de connaissances pour améliorer la précision factuelle, car ils sont une source fiable de faits.
Publicité
Continuer la lecture ci-dessous
«Les graphiques de connaissances (KG), qui se composent de données structurées, sont d’autres sources d’information. Les KG sont de nature factuelle, car les informations sont généralement extraites de sources plus fiables, et les filtres de post-traitement et les éditeurs humains garantissent la suppression des contenus inappropriés et incorrects. «
Google utilise-t-il KELM?
Google n’a pas indiqué si KELM est utilisé ou non. KELM est une approche de la pré-formation aux modèles de langage qui est très prometteuse et a été résumée sur le blog Google AI.
Biais, exactitude factuelle et résultats de recherche
Cette recherche est importante car elle réduit les biais et augmente l’exactitude factuelle pourrait impact sur le classement des sites.
Mais jusqu’à ce que KELM soit mis en service, il n’y a aucun moyen de prédire quel genre d’impact il aurait.
Google ne vérifie actuellement pas les résultats de recherche.
KELM, s’il devait être introduit, pourrait avoir un impact sur les sites qui promeuvent des déclarations et des idées factuellement incorrectes.
KELM Pourrait Impact plus que la recherche
Le KELM Corpus a été publié sous une licence Creative Commons (CC BY-SA 2.0).
Publicité
Continuer la lecture ci-dessous
Cela signifie, en théorie, toute autre entreprise (comme Bing, Facebook ou Twitter) peut également l’utiliser pour améliorer sa pré-formation au traitement du langage naturel.
C’est possible Ensuite, l’influence de KELM pourrait s’étendre sur de nombreuses plateformes de recherche et de médias sociaux.
Liens indirects avec MUM
Google a également indiqué que l’algorithme MUM de nouvelle génération ne sera pas publié tant que Google ne sera pas convaincu que le biais n’a pas d’impact négatif sur les réponses qu’il donne.
Selon l’annonce Google MUM:
«Tout comme nous avons soigneusement testé les nombreuses applications de BERT lancées depuis 2019, MUM subira le même processus que nous appliquons ces modèles dans la recherche.
Plus précisément, nous rechercherons des modèles susceptibles d’indiquer un biais dans l’apprentissage automatique afin d’éviter d’introduire un biais dans nos systèmes. »
L’approche KELM cible spécifiquement la réduction du biais, ce qui pourrait la rendre utile pour le développement de l’algorithme MUM.
L’apprentissage automatique peut générer des résultats biaisés
Le document de recherche indique que les données que les modèles de langage naturel comme BERT et GPT-3 utilisent pour la formation peuvent aboutir à « contenu toxique»Et les préjugés.
En informatique, il existe un vieil acronyme, GIGO, qui signifie Garbage In – Garbage Out. Cela signifie que la qualité de la sortie est déterminée par la qualité de l’entrée.
Si ce avec quoi vous entraînez l’algorithme est de haute qualité, le résultat sera de haute qualité.
Ce que les chercheurs proposent, c’est d’améliorer la qualité des données sur lesquelles des technologies comme BERT et MUM sont formées afin d’éliminer les biais.
Graphique des connaissances
Le graphe de connaissances est une collection de faits dans un format de données structuré. Les données structurées sont un langage de balisage qui communique des informations spécifiques d’une manière facilement consommable par les machines.
Dans ce cas, les informations sont des faits sur des personnes, des lieux et des choses.
Le Google Knowledge Graph a été introduit en 2012 pour aider Google à comprendre les relations entre les choses. Ainsi, lorsque quelqu’un pose des questions sur Washington, Google pourrait être en mesure de discerner si la personne posant la question posait des questions sur Washington, la personne, l’État ou le district de Columbia.
Publicité
Continuer la lecture ci-dessous
Le graphique de connaissances de Google a été annoncé comme étant composé de données provenant de sources fiables de faits.
L’annonce de Google en 2012 a caractérisé le graphique des connaissances comme une première étape vers la construction de la prochaine génération de recherche, dont nous profitons actuellement.
Graphique des connaissances et précision factuelle
Les données du graphique de connaissances sont utilisées dans ce document de recherche pour améliorer les algorithmes de Google, car les informations sont dignes de confiance et fiables.
Le document de recherche de Google propose d’intégrer les informations du graphique de connaissances dans le processus de formation pour éliminer les biais et augmenter la précision factuelle.
Ce que propose la recherche Google est double.
- Premièrement, ils doivent convertir les bases de connaissances en texte en langage naturel.
- Deuxièmement, le corpus qui en résulte, nommé Knowledge-Enhanced Language Model Pre-training (KELM), peut ensuite être intégré dans le pré-apprentissage de l’algorithme pour réduire les biais.
Les chercheurs expliquent le problème comme ceci:
«Les grands modèles de traitement du langage naturel (NLP) pré-entraînés, tels que BERT, RoBERTa, GPT-3, T5 et REALM, exploitent des corpus de langage naturel dérivés du Web et affinés sur des données spécifiques à une tâche…
Cependant, le texte en langage naturel représente à lui seul une couverture limitée des connaissances… De plus, l’existence d’informations non factuelles et d’un contenu toxique dans le texte peuvent éventuellement entraîner des biais dans les modèles qui en résultent. »
Publicité
Continuer la lecture ci-dessous
Des données structurées Knowledge Graph au texte en langage naturel
Les chercheurs affirment qu’un problème lié à l’intégration des informations de la base de connaissances dans la formation est que les données de la base de connaissances se présentent sous la forme de données structurées.
La solution consiste à convertir les données structurées du graphe de connaissances en texte en langage naturel à l’aide d’une tâche en langage naturel appelée génération de données en texte.
Ils ont expliqué que parce que la génération de données en texte est un défi, ils ont créé ce qu’ils ont appelé un nouveau « pipeline » appelé « Texte de KG Generator (TEKGEN) » résoudre le problème.
Citation: Génération de corpus synthétiques à base de graphes de connaissances pour la formation préalable au modèle de langage amélioré par les connaissances (PDF)
TEKGEN Natural Language Text Amélioration de la précision factuelle
TEKGEN est la technologie que les chercheurs ont créée pour convertir des données structurées en texte en langage naturel. C’est ce résultat final, un texte factuel, qui peut être utilisé pour créer le corpus KELM qui peut ensuite être utilisé dans le cadre de la pré-formation à l’apprentissage automatique pour aider à empêcher les biais de se frayer un chemin dans les algorithmes.
Les chercheurs ont noté que l’ajout de ces informations supplémentaires sur les graphiques de connaissances (corpus) dans les données d’entraînement a permis d’améliorer la précision factuelle.
Publicité
Continuer la lecture ci-dessous
L’article TEKGEN / KELM déclare:
«Nous montrons en outre que la verbalisation d’un KG encyclopédique complet comme Wikidata peut être utilisé pour intégrer des KG structurés et des corpus de langage naturel.
… Notre approche convertit le KG en texte naturel, lui permettant d’être intégré de manière transparente dans les modèles de langage existants. Il présente les avantages supplémentaires d’une précision factuelle améliorée et d’une toxicité réduite dans le modèle de langage qui en résulte. »
L’article de KELM a publié une illustration montrant comment un nœud de données structurées est concaténé puis converti à partir de là en texte naturel (verbalisé).
J’ai divisé l’illustration en deux parties.
Ci-dessous, une image représentant des données structurées de graphe de connaissances. Les données sont concaténées en texte.
Capture d’écran de la première partie du processus de conversion TEKGEN
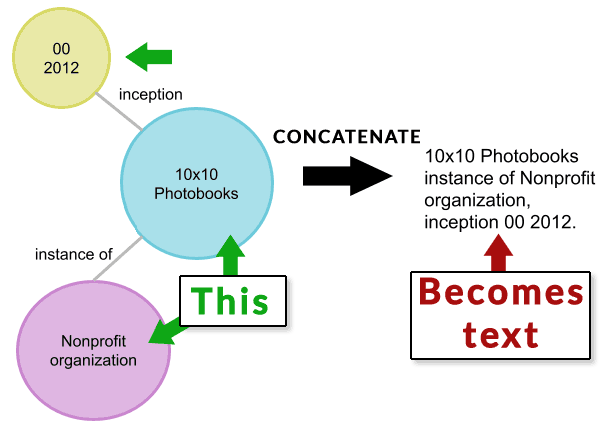
L’image ci-dessous représente la prochaine étape du processus TEKGEN qui prend le texte concaténé et le convertit en texte en langage naturel.
Publicité
Continuer la lecture ci-dessous
Capture d’écran du texte transformé en texte en langage naturel

Générer le corpus KELM
Il y a une autre illustration qui montre comment le texte en langage naturel KELM qui peut être utilisé pour la pré-formation est généré.
Le papier TEKGEN montre cette illustration plus une description:
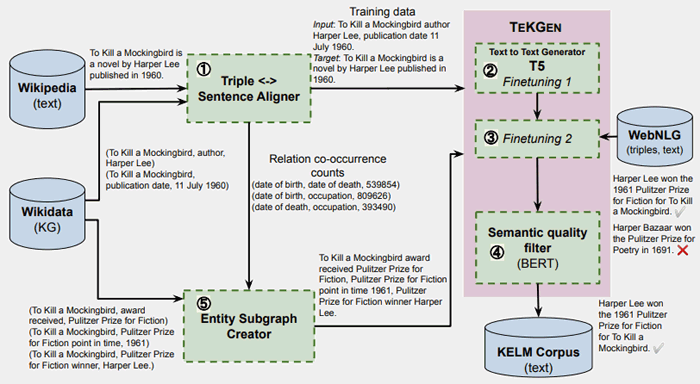
- «À l’étape 1, les triplets de KG sont alignés avec le texte de Wikipedia en utilisant une supervision à distance.
- Aux étapes 2 et 3, T5 est affiné séquentiellement d’abord sur ce corpus, suivi d’un petit nombre d’étapes sur le corpus WebNLG,
- À l’étape 4, BERT est affiné pour générer un score de qualité sémantique pour les phrases générées avec des triplets.
- Les étapes 2, 3 et 4 forment ensemble TEKGEN.
- Pour générer le corpus KELM, à l’étape 5, des sous-graphiques d’entités sont créés à l’aide des comptages d’alignement de paires de relations à partir du corpus d’apprentissage généré à l’étape 1.
Les triplets de sous-graphes sont ensuite convertis en texte naturel à l’aide de TEKGEN. »
Publicité
Continuer la lecture ci-dessous
KELM travaille pour réduire les biais et promouvoir la précision
L’article KELM publié sur le blog AI de Google indique que KELM a des applications dans le monde réel, en particulier pour les tâches de réponse aux questions qui sont explicitement liées à la recherche d’informations (recherche) et au traitement du langage naturel (technologies telles que BERT et MUM).
Google recherche de nombreuses choses, dont certaines semblent être des explorations de ce qui est possible, mais semblent autrement être des impasses. Les recherches qui ne seront probablement pas intégrées à l’algorithme de Google se terminent généralement par une déclaration selon laquelle des recherches supplémentaires sont nécessaires car la technologie ne répond pas aux attentes d’une manière ou d’une autre.
Mais ce n’est pas le cas des recherches KELM et TEKGEN. L’article est en fait optimiste quant à l’application réelle des découvertes. Cela tend à lui donner une probabilité plus élevée que KELM puisse éventuellement en faire une recherche sous une forme ou une autre.
C’est ainsi que les chercheurs ont conclu l’article sur KELM pour réduire les biais:
«Cela a des applications concrètes pour les tâches à forte intensité de connaissances, telles que la réponse aux questions, où la fourniture de connaissances factuelles est essentielle. De plus, ces corpus peuvent être appliqués lors de la pré-formation de grands modèles de langage, et peuvent potentiellement réduire la toxicité et améliorer la factualité. »
Publicité
Continuer la lecture ci-dessous
KELM sera-t-il bientôt utilisé?
L’annonce récente par Google de l’algorithme MUM nécessite de la précision, ce pour quoi le corpus KELM a été créé. Mais l’application de KELM ne se limite pas à MUM.
Le fait que la réduction des biais et de l’exactitude factuelle soit une préoccupation essentielle dans la société d’aujourd’hui et que les chercheurs soient optimistes quant aux résultats tend à lui donner une probabilité plus élevée d’être utilisé sous une forme ou une autre dans le futur à la recherche.
Citations
Google AI Article on KELM
KELM: Intégration des graphes de connaissances avec les corpus de pré-formation des modèles de langage
Document de recherche KELM (PDF)
Génération de corpus synthétiques à base de graphes de connaissances pour la formation préalable au modèle de langage amélioré par les connaissances
TEKGEN Training Corpus sur GitHub
Auteur/autrice