
Les bibliothèques Python sont un moyen amusant et accessible de commencer à apprendre et à utiliser Python pour le référencement.
Une bibliothèque Python est une collection de fonctions et de code utiles qui vous permettent d’effectuer un certain nombre de tâches sans avoir besoin d’écrire le code à partir de zéro.
Il existe plus de 100000 bibliothèques disponibles à utiliser en Python, qui peuvent être utilisées pour des fonctions allant de l’analyse de données à la création de jeux vidéo.
Dans cet article, vous trouverez plusieurs bibliothèques différentes que j’ai utilisées pour mener à bien des projets et des tâches de référencement. Ils sont tous adaptés aux débutants et vous trouverez de nombreux documents et ressources pour vous aider à démarrer.
Pourquoi les bibliothèques Python sont-elles utiles pour le référencement?
Chaque bibliothèque Python contient des fonctions et des variables de tous types (tableaux, dictionnaires, objets, etc.) qui peuvent être utilisées pour effectuer différentes tâches.
Publicité
Continuer la lecture ci-dessous
Pour le référencement, par exemple, ils peuvent être utilisés pour automatiser certaines choses, prédire les résultats et fournir des informations intelligentes.
Il est possible de travailler uniquement avec Python vanilla, mais les bibliothèques peuvent être utilisées pour rendre les tâches beaucoup plus faciles et plus rapides à écrire et à terminer.
Bibliothèques Python pour les tâches de référencement
Il existe un certain nombre de bibliothèques Python utiles pour les tâches de référencement, notamment l’analyse de données, le scraping Web et la visualisation d’informations.
Ce n’est pas une liste exhaustive, mais ce sont les bibliothèques que je trouve que j’utilise le plus à des fins de référencement.
Pandas
Pandas est une bibliothèque Python utilisée pour travailler avec des données de table. Il permet une manipulation de données de haut niveau où la structure de données clé est un DataFrame.
Les DataFrames sont similaires aux feuilles de calcul Excel, cependant, ils ne sont pas limités aux limites de lignes et d’octets et sont également beaucoup plus rapides et efficaces.
La meilleure façon de démarrer avec Pandas est de prendre un simple CSV de données (une exploration de votre site Web, par exemple) et de l’enregistrer dans Python en tant que DataFrame.
Publicité
Continuer la lecture ci-dessous
Une fois que vous l’avez stocké dans Python, vous pouvez effectuer un certain nombre de tâches d’analyse différentes, notamment l’agrégation, le pivotement et le nettoyage des données.
Par exemple, si j’ai une exploration complète de mon site Web et que je souhaite extraire uniquement les pages indexables, j’utiliserai une fonction Pandas intégrée pour inclure uniquement ces URL dans mon DataFrame.
import pandas as pd
df = pd.read_csv('/Users/rutheverett/Documents/Folder/file_name.csv')
df.head
indexable = df[(df.indexable == True)]
indexable
Demandes
La bibliothèque suivante s’appelle Requests et est utilisée pour effectuer des requêtes HTTP en Python.
Requests utilise différentes méthodes de requête telles que GET et POST pour effectuer une requête, les résultats étant stockés dans Python.
Un exemple de ceci en action est une simple requête GET d’URL, cela imprimera le code d’état d’une page:
import requests
response = requests.get('https://www.deepcrawl.com') print(response)
Vous pouvez ensuite utiliser ce résultat pour créer une fonction de prise de décision, où un code d’état 200 signifie que la page est disponible mais un 404 signifie que la page n’est pas trouvée.
if response.status_code == 200:
print('Success!')
elif response.status_code == 404:
print('Not Found.')
Vous pouvez également utiliser différentes requêtes telles que des en-têtes, qui affichent des informations utiles sur la page comme le type de contenu ou le temps nécessaire pour mettre en cache la réponse.
headers = response.headers print(headers) response.headers['Content-Type']
Il est également possible de simuler un agent utilisateur spécifique, tel que Googlebot, afin d’extraire la réponse que ce bot spécifique verra lors de l’exploration de la page.
headers = {'User-Agent': 'Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)'} ua_response = requests.get('https://www.deepcrawl.com/', headers=headers) print(ua_response)

Belle soupe
Beautiful Soup est une bibliothèque utilisée pour extraire des données à partir de fichiers HTML et XML.
Fait amusant: la bibliothèque BeautifulSoup a en fait été nommée d’après le poème d’Alice’s Adventures in Wonderland de Lewis Carroll.
Publicité
Continuer la lecture ci-dessous
En tant que bibliothèque, BeautifulSoup est utilisé pour donner un sens aux fichiers Web et est le plus souvent utilisé pour le scraping Web, car il peut transformer un document HTML en différents objets Python.
Par exemple, vous pouvez prendre une URL et utiliser Beautiful Soup avec la bibliothèque Requests pour extraire le titre de la page.
from bs4 import BeautifulSoup import requests url="https://www.deepcrawl.com" req = requests.get(url) soup = BeautifulSoup(req.text, "html.parser") title = soup.title print(title)

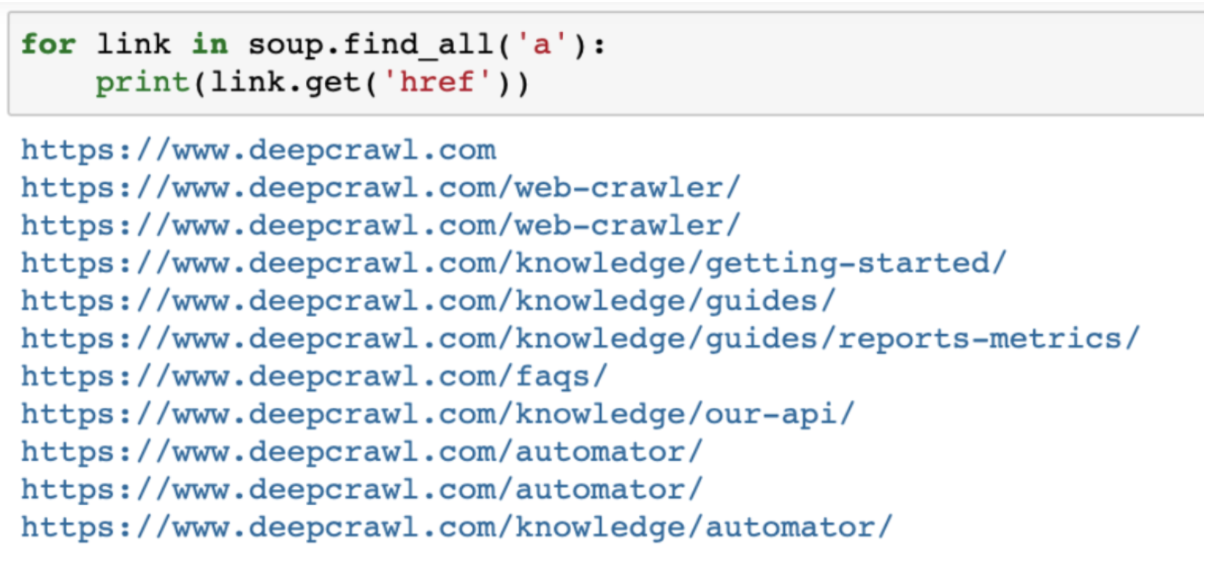
De plus, en utilisant la méthode find_all, BeautifulSoup vous permet d’extraire certains éléments d’une page, tels que tous les liens href de la page:
Publicité
Continuer la lecture ci-dessous
url="https://www.deepcrawl.com/knowledge/technical-seo-library/"
req = requests.get(url)
soup = BeautifulSoup(req.text, "html.parser")
for link in soup.find_all('a'):
print(link.get('href'))
Les assembler
Ces trois bibliothèques peuvent également être utilisées ensemble, avec des requêtes utilisées pour envoyer la requête HTTP à la page à partir de laquelle nous aimerions utiliser BeautifulSoup pour extraire des informations.
Nous pouvons ensuite transformer ces données brutes en un Pandas DataFrame pour effectuer une analyse plus approfondie.
URL = 'https://www.deepcrawl.com/blog/'
req = requests.get(url)
soup = BeautifulSoup(req.text, "html.parser")
links = soup.find_all('a')
df = pd.DataFrame({'links':links})
df
Matplotlib et Seaborn
Matplotlib et Seaborn sont deux bibliothèques Python utilisées pour créer des visualisations.
Matplotlib vous permet de créer un certain nombre de visualisations de données différentes telles que des graphiques à barres, des graphiques linéaires, des histogrammes et même des cartes thermiques.
Publicité
Continuer la lecture ci-dessous
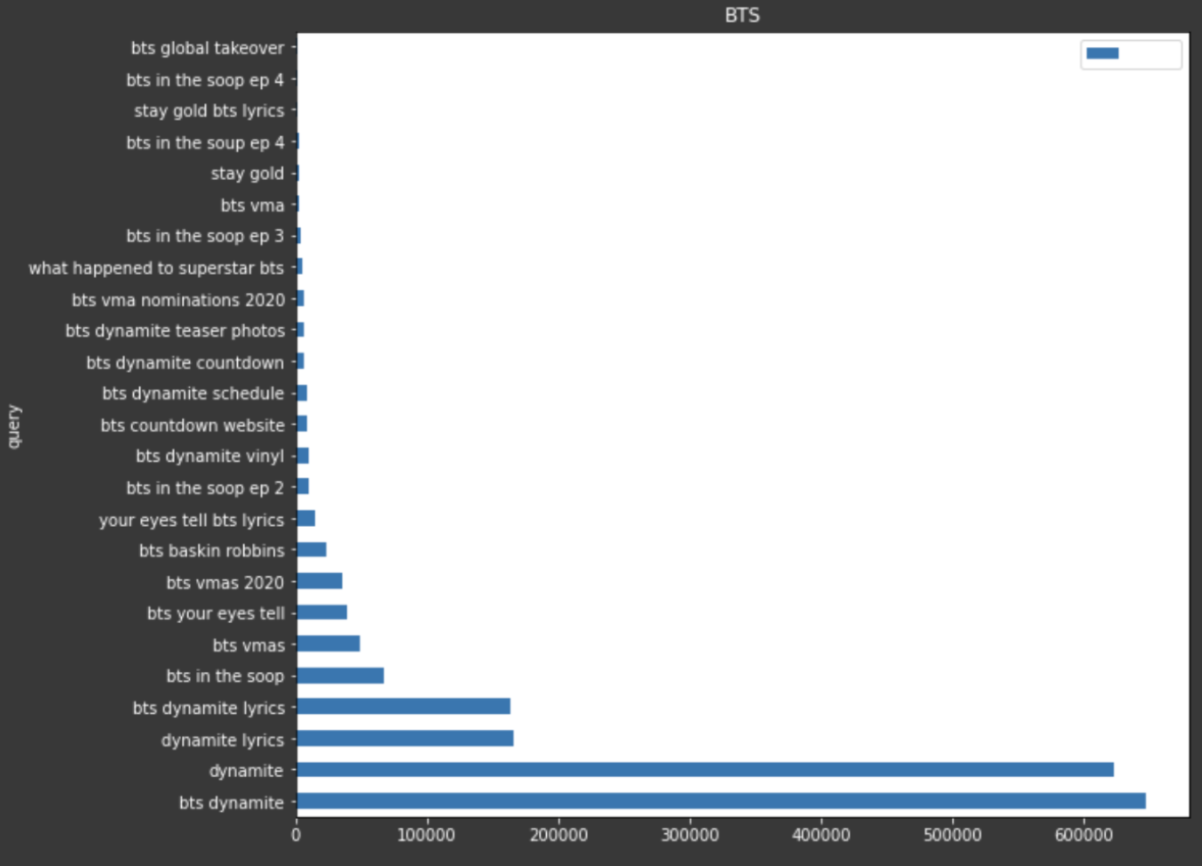
Par exemple, si je voulais utiliser certaines données de Google Trends pour afficher les requêtes les plus populaires sur une période de 30 jours, je pourrais créer un graphique à barres dans Matplotlib pour visualiser tout cela.
Seaborn, qui est basé sur Matplotlib, fournit encore plus de modèles de visualisation tels que des nuages de points, des boîtes à moustaches et des graphiques de violon en plus des graphiques en lignes et en barres.
Il diffère légèrement de Matplotlib car il utilise moins de syntaxe et possède des thèmes par défaut intégrés.
Publicité
Continuer la lecture ci-dessous
Une façon dont j’ai utilisé Seaborn est de créer des graphiques linéaires afin de visualiser les accès de fichiers journaux à certains segments d’un site Web au fil du temps.
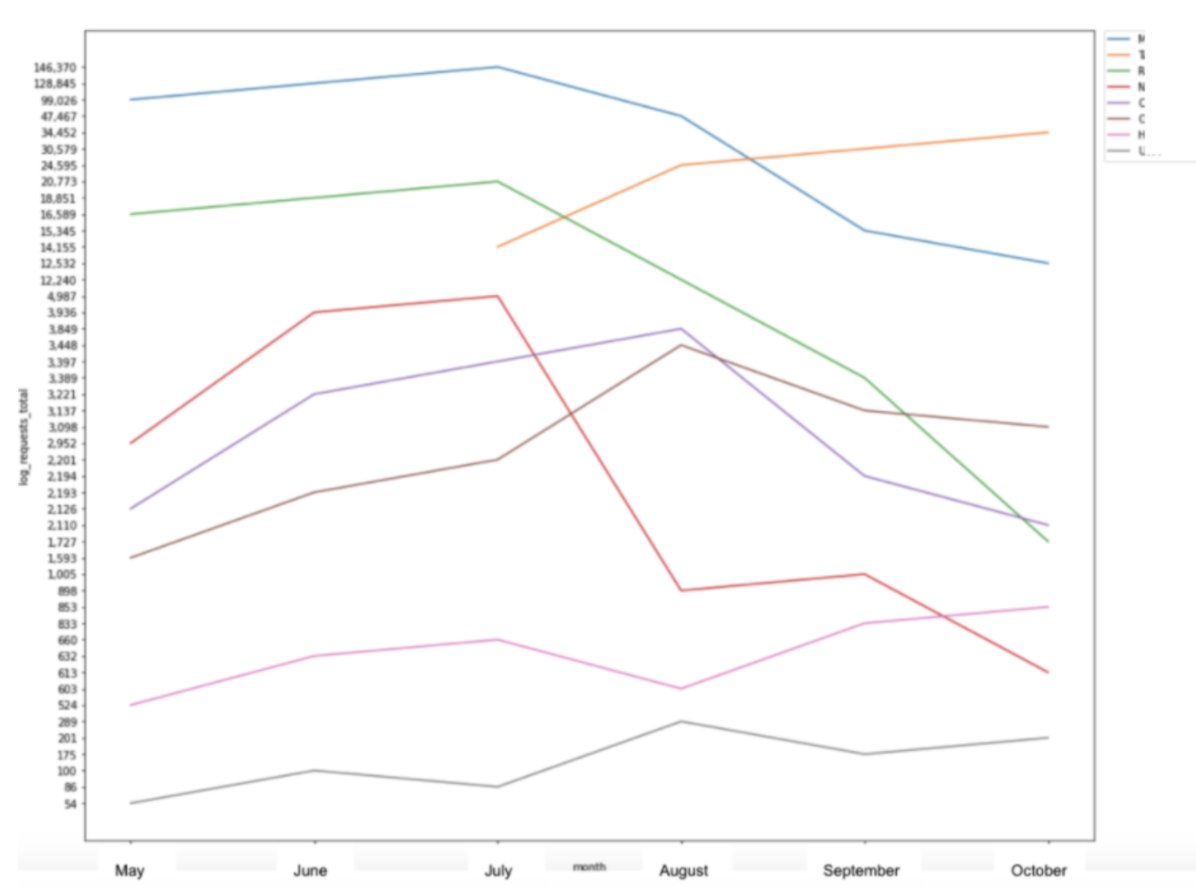
sns.lineplot(x = "month", y = "log_requests_total", hue="category", data=pivot_status) plt.show()
Cet exemple particulier prend les données d’un tableau croisé dynamique, que j’ai pu créer en Python à l’aide de la bibliothèque Pandas, et constitue une autre façon dont ces bibliothèques fonctionnent ensemble pour créer une image facile à comprendre à partir des données.
Outils publicitaires
Advertools est une bibliothèque créée par Elias Dabbas qui peut être utilisé pour aider à gérer, comprendre et prendre des décisions en fonction des données dont nous disposons en tant que professionnels du référencement et spécialistes du marketing numérique.
Publicité
Continuer la lecture ci-dessous
Analyse du plan du site
Cette bibliothèque vous permet d’effectuer un certain nombre de tâches différentes telles que le téléchargement, l’analyse et l’analyse de sitemaps XML pour extraire des modèles ou analyser la fréquence à laquelle le contenu est ajouté ou modifié.
Analyse Robots.txt
Une autre chose intéressante que vous pouvez faire avec cette bibliothèque est d’utiliser une fonction pour extraire le fichier robots.txt d’un site Web dans un DataFrame, afin de comprendre et d’analyser facilement l’ensemble de règles.
Vous pouvez également exécuter un test dans la bibliothèque afin de vérifier si un agent utilisateur particulier est capable de récupérer certaines URL ou certains chemins de dossier.
Analyse d’URL
Advertools vous permet également d’analyser et d’analyser les URL afin d’extraire des informations et de mieux comprendre les données d’analyse, SERP et d’analyse pour certains ensembles d’URL.
Vous pouvez également fractionner les URL à l’aide de la bibliothèque pour déterminer des éléments tels que le schéma HTTP utilisé, le chemin principal, des paramètres supplémentaires et des chaînes de requête.
Sélénium
Selenium est une bibliothèque Python généralement utilisée à des fins d’automatisation. Le cas d’utilisation le plus courant est le test d’applications Web.
Publicité
Continuer la lecture ci-dessous
Un exemple populaire d’automatisation d’un flux par Selenium est un script qui ouvre un navigateur et effectue un certain nombre d’étapes différentes dans une séquence définie, comme remplir des formulaires ou cliquer sur certains boutons.
Selenium utilise le même principe que celui utilisé dans la bibliothèque Requests que nous avons abordée précédemment.
Cependant, il enverra non seulement la demande et attendra la réponse, mais rendra également la page Web demandée.
Pour démarrer avec Selenium, vous aurez besoin d’un WebDriver afin d’effectuer les interactions avec le navigateur.
Chaque navigateur a son propre WebDriver; Chrome a ChromeDriver et Firefox a GeckoDriver, par exemple.
Ceux-ci sont faciles à télécharger et à configurer avec votre code Python. Voici un article utile expliquant le processus de configuration, avec un exemple de projet.
Scrapy
La dernière bibliothèque que je voulais couvrir dans cet article est Scrapy.
Bien que nous puissions utiliser le module Requests pour explorer et extraire des données internes d’une page Web, afin de transmettre ces données et d’extraire des informations utiles, nous devons également les combiner avec BeautifulSoup.
Publicité
Continuer la lecture ci-dessous
Scrapy vous permet essentiellement de faire les deux dans une seule bibliothèque.
Scrapy est également considérablement plus rapide et plus puissant, complète les demandes d’exploration, extrait et analyse les données dans une séquence définie et vous permet de protéger les données.
Dans Scrapy, vous pouvez définir un certain nombre d’instructions telles que le nom du domaine que vous souhaitez explorer, l’URL de démarrage et certains dossiers de pages que l’araignée est autorisée ou non à explorer.
Scrapy peut être utilisé pour extraire tous les liens sur une certaine page et les stocker dans un fichier de sortie, par exemple.
class SuperSpider(CrawlSpider):
name="extractor"
allowed_domains = ['www.deepcrawl.com']
start_urls = ['https://www.deepcrawl.com/knowledge/technical-seo-library/']
base_url="https://www.deepcrawl.com"
def parse(self, response):
for link in response.xpath('//div/p/a'):
yield {
"link": self.base_url + link.xpath('.//@href').get()
}
Vous pouvez aller plus loin et suivre les liens trouvés sur une page Web pour extraire des informations de toutes les pages qui sont liées à partir de l’URL de démarrage, un peu comme une réplication à petite échelle de la recherche Google et des liens suivants sur une page.
from scrapy.spiders import CrawlSpider, Rule
class SuperSpider(CrawlSpider):
name="follower"
allowed_domains = ['en.wikipedia.org']
start_urls = ['https://en.wikipedia.org/wiki/Web_scraping']
base_url="https://en.wikipedia.org"
custom_settings = {
'DEPTH_LIMIT': 1
}
def parse(self, response):
for next_page in response.xpath('.//div/p/a'):
yield response.follow(next_page, self.parse)
for quote in response.xpath('.//h1/text()'):
yield {'quote': quote.extract() }
En savoir plus sur ces projets, parmi d’autres exemples de projets, ici.
Dernières pensées
Comme l’a toujours dit Hamlet Batista, «la meilleure façon d’apprendre est de faire».
Publicité
Continuer la lecture ci-dessous
J’espère que la découverte de certaines des bibliothèques disponibles vous a inspiré pour commencer à apprendre Python, ou pour approfondir vos connaissances.
Contributions Python de l’industrie du référencement
Hamlet a également aimé partager des ressources et des projets de ceux de la communauté SEO Python. Pour honorer sa passion d’encourager les autres, je voulais partager certaines des choses incroyables que j’ai vues de la communauté.
En hommage à Hamlet et à la communauté SEO Python, il a contribué à cultiver, Charly Wargnier a créé SEO Pythonistas pour collecter les contributions des incroyables projets Python créés par la communauté SEO.
Les contributions inestimables de Hamlet à la communauté SEO sont présentées.
Moshe Ma-yafit a créé un script super cool pour l’analyse des fichiers journaux, et dans cet article explique comment le script fonctionne. Les visualisations qu’il est capable d’afficher, notamment les hits de Google Bot par appareil, les hits quotidiens par code de réponse, le code de réponse% total, etc.
Koray Tüberk GÜBÜR travaille actuellement sur un vérificateur de l’état de santé du plan de site. Il a également animé un webinaire RankSense avec Elias Dabbas où il a partagé un script qui enregistre les SERPs et analyse les algorithmes.
Publicité
Continuer la lecture ci-dessous
Il enregistre essentiellement les SERPs avec des décalages horaires réguliers, et vous pouvez explorer toutes les pages de destination, mélanger les données et créer des corrélations.
John McAlpin a écrit un article détaillant comment utiliser Python et Data Studio pour espionner vos concurrents.
JC Chouinard a écrit un guide complet sur l’utilisation de l’API Reddit. Avec cela, vous pouvez effectuer des tâches telles que l’extraction de données de Reddit et la publication sur un Subreddit.
Rob May travaille sur un nouvel outil d’analyse GSC et construit quelques nouveaux domaines / sites réels dans Wix pour se mesurer à son concurrent WordPress haut de gamme tout en le documentant.
Masaki Okazawa a également partagé un script qui analyse les données de la console de recherche Google avec Python.
🎉 Heureux #RSTwittorial Jeudi avec @saksters 🥳
Analyse des données de la console de recherche Google avec #Python 🐍🔥
Voici la sortie 👇 pic.twitter.com/9l5Xc6UsmT
– RankSense (@RankSense) 25 février 2021
Plus de ressources:
Publicité
Continuer la lecture ci-dessous
Crédits d’image
Toutes les captures d’écran prises par l’auteur, mars 2021
Auteur/autrice




